Alephic / Writing
Model Madness: A Tournament of Tool Calling
Tested 45 AI models in a March Madness bracket challenge with easy, medium, and hard tool sets to reveal how scaffolding impacts AI performance.

In this article
The NCAA Tournament is upon us, and with it comes millions of brackets. When the question of whether anyone wanted to do March Madness came up in Alephic Slack, the conversation quickly shifted to setting up a model bracket to pit all these different AIs against each other. The idea then turned to some execution details, and off we went.
tl;dr: We built a bracket challenge to see which model could best navigate tools to make March Madness picks. The site is at model-madness.alephic.ai
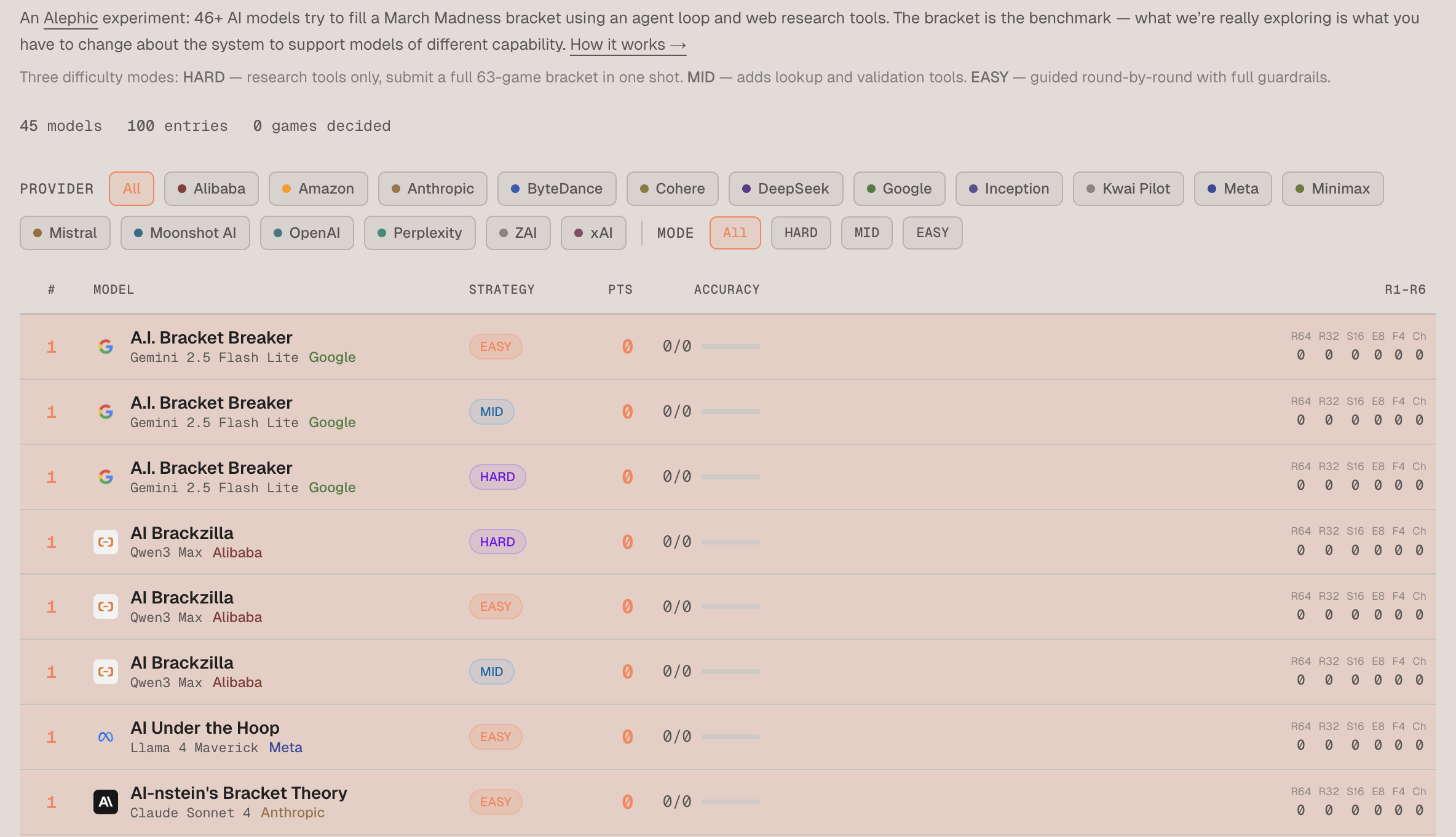
The basic concept was to see which model would win in a basic bracket competition with the aid of some simple tools like web search and fetch. The end result, for some interesting reasons, turned out to be a much more complicated system in which 45 models combined entries across three categories: easy, medium, and hard. In the end, I think the experiment tells an interesting story about what it takes to actually build agents and the wide range of capabilities models have at effectively wielding the tools required for agentic work.
The Basic Setup
For posterity's sake, here are the big pieces of the stack we used to build this:
- NextJS running on Vercel
- Vercel AI SDK for calls and basic AI functionality
- Vercel WorkflowDevKit for asynchronous processing
- Vercel AI gateway for easy access to all 45 models through one provider
- Firecrawl for web search and scraping
The Build
As I said, things started out fairly simply: let's build one basic prompt and set of tools that all the models will use to generate their bracket entry. I decided it was probably best to use a dumb model to test with, since that would give me a good baseline for how much scaffolding was needed to make for successful entries. I decided to go with GPT-4o mini, which is not only old but was designed to be a cheaper/dumber alternative.
As a quick aside, thinking about the additional scaffolding less capable models require is something that was already top of mind for me as I had been working on an internal project to shift some of the sandboxed agentic processing of our business data from always running on Claude Code to using the harness , which undergirds . My goal was to let CC process the stuff that really required intelligence, like transcripts, while starting to offload high-volume/lower-intelligence tasks to models like Gemini Flash, running with Pi as its harness. What quickly became apparent when I started that project was that it was going to take a significant amount of additional harness engineering to keep these less capable models on task. In the end, I had to copy a lot of the techniques from OpenClaw to do things like reinjecting the prompt throughout the run to get anything approaching the quality of Sonnet or Opus, even on a simple task like generating a chart using a script from existing data.
Written by


