Alephic / Writing
The $1 Sweet Spot
Gemini Flash delivers around 80% of frontier LLM intelligence at just 10–25% of the cost, making it the defining model in the $1 intelligence tier.

In this article
Gemini Flash has been on my mind a lot lately. Partly because Flash 3 came out and I've been doing a bunch with it (including processing 15 years of Evernote notes over a weekend), and partly because GPT 5.4 dropped, which means we have a new potential leader in the frontier LLM category. That last bit matters because the title of best model in the world feels like a horse race. Depending on the month and day, it could be OpenAI, Anthropic, or Google ahead by a nose. That race matters a lot to my day-to-day, but I'm not convinced swapping one for another would change much. They're all excellent, and they all cost roughly the same.
Why Gemini Flash Is Different
And then there's Gemini Flash. Neither Anthropic’s Claude Haiku or OpenAI’s GPT-5 Mini can come close to touching the smarts per dollar that Flash offers.
My favorite Flash story is from about a year ago, when a customer called us needing something in a pinch. They had 2 terabytes of b-roll photo and video that needed to be tagged and organized in a week for an upcoming campaign. They were an existing customer, and we were happy to help (we take seriously our commitment to help solve a CMO's most pressing challenges—no matter what that challenge may be). But before taking it on, I wanted to make sure the cost made sense. So I took a gig of the 2 terabytes, built a taxonomy, and ran it through Gemini Flash 2.5. And then I ran it again. And then a third time—because I kept thinking I'd screwed up the math. The total projected cost in tokens for the whole project: $60.
Flash (now up to 3) is unlike anything else in the market from one of the three main players. It's not something I use in my coding harness (yet)—though I am experimenting with using it in harnesses like Pi for sandboxed workloads at scale—but when you have a ton of work to do and you need it done well, it's almost impossible to beat. Artificial Analysis pulls together evals and benchmarks to rank models. It's imperfect, but directionally accurate (see footnote on chart). And the data makes Flash's sweet spot obvious: you get something like 80% of frontier intelligence at 10–25% of the cost. It's the only non-open weight model in what I've labeled "the sweet spot."
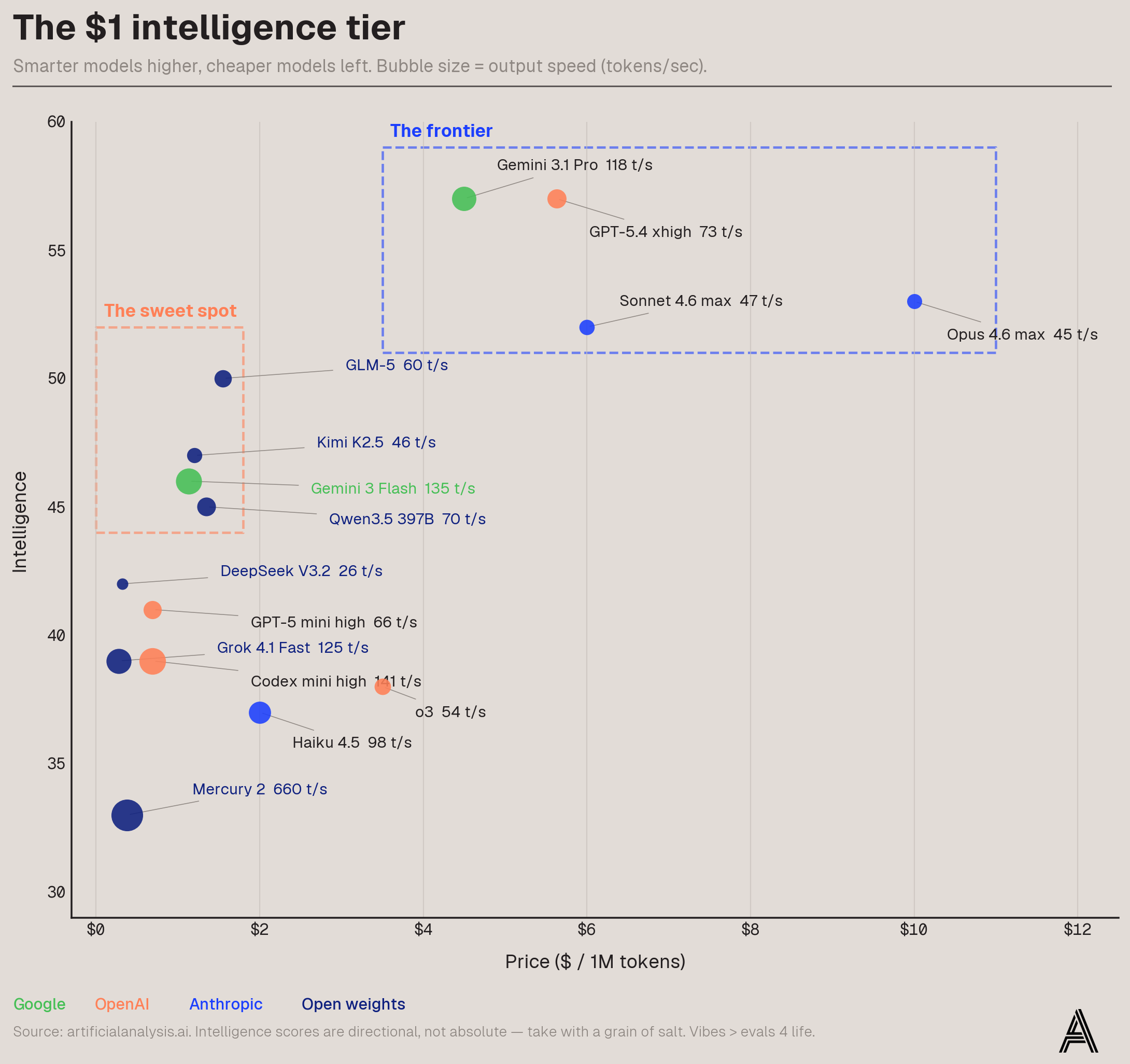
Before anyone freaks out about where Opus sits on here and writes all this off: I agree that Opus is clearly smarter than the score they have, but no matter how smart they are they’re still very clearly in the Frontier box and that’s the main point. Also: vibes > evals 4 life.
Written by


