The AI revolution will be dictated by three physical constraints—compute packaging capacity, energy availability, and organizational agility—that concentrate...
Bottom Line Up Front (BLUF): The AI revolution will be throttled by three physical constraints: compute (35,000 chip packages per month), energy (4-7 year grid connections), and humans (18-month+ approval cycles). But scarcity alone doesn't tell the whole story. These resources concentrate through gravity wells—scarce assets flow to whoever can pay the most and deploy the fastest, creating winner-take-all dynamics. This new economic reality means atoms constrain bits, physics beats algorithms, and the companies controlling these choke points will shape AI's trajectory for the next decade. The future belongs not to those with the best models, but to those who control the pipes.
The Physics of AI Value
On September 20, 2024, Microsoft agreed to pay nearly double market rates for electricity from a nuclear plant most people thought was dead. This isn't desperation. It's the new economics of AI, where physical bottlenecks matter more than algorithms.
The entire AI revolution depends on three physical bottlenecks that money alone can't fix. Every enterprise running AI agents, every startup training custom models, and every hedge fund running inference at scale must pass through these gates. The companies that own them will collect rent on the future.
Here's how.
Three Cascading Bottlenecks
Compute: The Packaging Crisis Nobody Sees
We can make chips faster than we can make them useful.
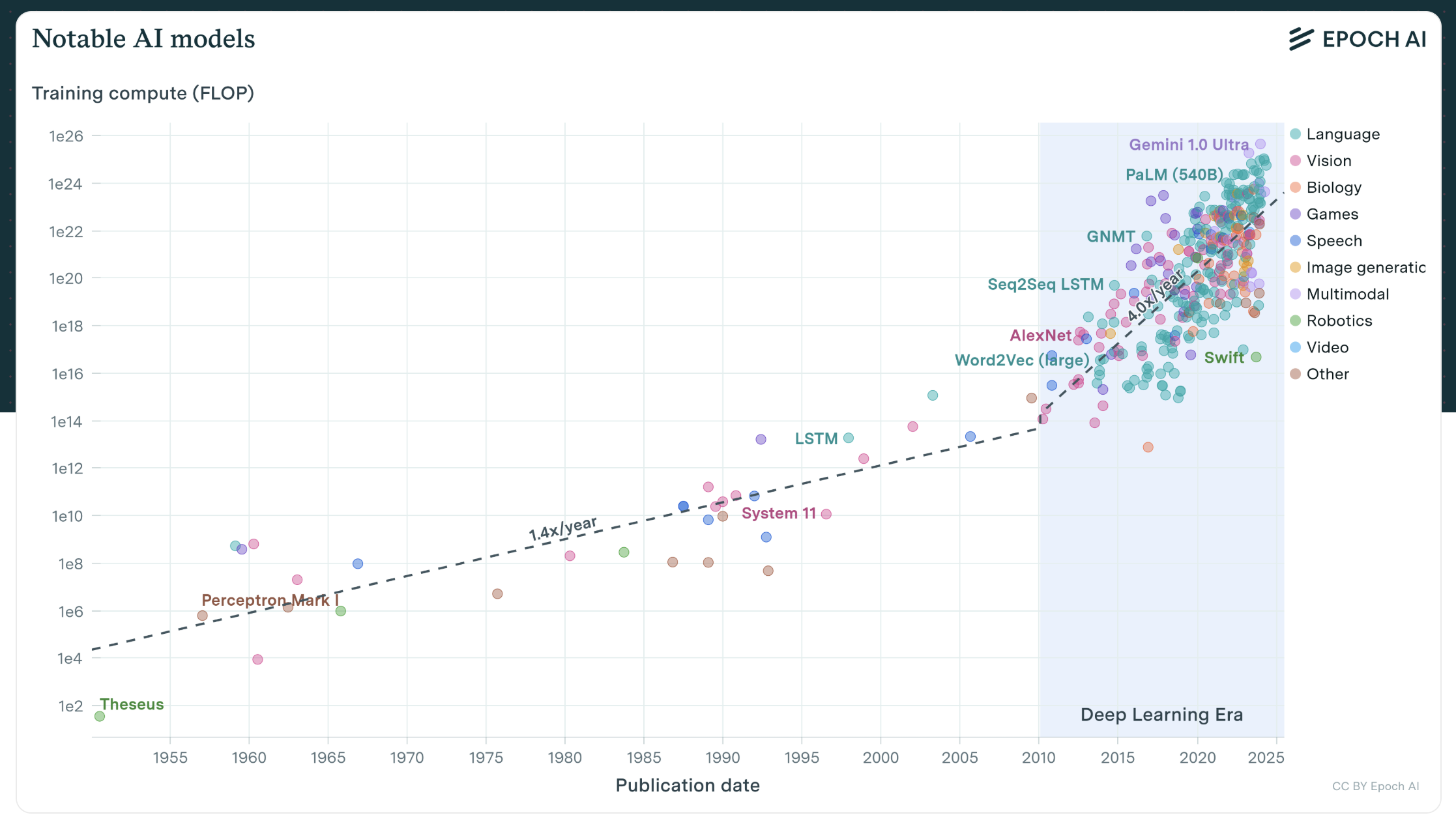
"The limiting factor for our growth is advanced packaging, not chip production," Jensen Huang admitted in Nvidia's Q3 2024 earnings call. TSMC can fabricate GPU processors by the millions, but their CoWoS—the technology that lets GPUs talk to memory fast enough for AI—crawls along at just 35,000 wafers per month.
The demand side tells a different story. Training compute has been doubling every 5–6 months since 2010. Today's largest models require 100 times more compute power than two years ago. By 2030, Epoch AI projects that inference will consume 5–10 times more compute than training.
The HBM (High Bandwidth Memory) bottleneck compounds the problem. HBM is memory that sits directly on the chip, similar to RAM attached to your processor. Only three companies can make it: SK Hynix (46-49% market share), Samsung (40% share, but struggling to get their chips approved by customers like Nvidia), and Micron (4-10% share). Each new generation requires tighter integration with packaging. This dual constraint creates the ultimate chokepoint: every AI accelerator needs both advanced packaging and high-bandwidth memory. No exceptions.
Solve packaging, and you hit an even harder wall...
Why can't they just connect? Because grid infrastructure requires different timelines than software. You need upgraded transmission lines, new substations, and environmental permits. The Lawrence Berkeley National Lab found average connection times of 4-7 years. In AI time, that's an eternity.
Yet even these moonshot bets face reality. SMR manufacturing requires specialized facilities—only a handful of companies worldwide can manufacture reactor pressure vessels. International deployments show familiar patterns: China's HTR-PM took 10 years longer than planned,and Russia's floating reactor experienced 9 years of delays. The optimistic "early 2030s" timeline for commercial deployment means tech giants must solve their power crisis with existing infrastructure for at least another half-decade.
Yet even with chips and power, there's one bottleneck money can't fix.
Talent: The Human Bandwidth Crisis
We can't package chips fast enough. We can't connect the power fast enough. However, there's a third bottleneck that exacerbates both problems: we can't make decisions quickly enough.
The binding constraint on AI deployment isn't just physical infrastructure—it's organizational velocity. While TSMC struggles to expand packaging capacity and tech giants scramble for nuclear deals, most enterprises are still debating committee structures while their competitors ship production code.
The $3 Trillion Friction Tax
The numbers reveal institutional sclerosis on a large scale. Harvard Business Review quantified what every enterprise feels: bureaucracy costs the US economy $3 trillion annually, 17% of GDP. In tech, the damage is more acute. Managerial and administrative roles have ballooned to one administrator for every four to seven frontline workers, up from ratios of 1:10 in the 1980s.
This isn't just overhead—it's a physics constraint on innovation velocity. When DocuSign employs 6,840 people to manage digital signatures while entire AI companies reach nine-figure revenues with dozens, we're witnessing two different species of organization. One moves at the speed of committees—the other moves at the speed of code.
In 1968, Melvin Conway observed that organizations "are constrained to produce designs which are copies of their communication structures." For fifty years, this meant your org chart became your architecture. Your approval chains became your user experience. Your bureaucracy literally encoded itself into your products.
AI doesn't just work around Conway's Law—it makes traditional organizational structures obsolete. When AI agents can coordinate without meetings, when natural language replaces rigid APIs, when a single person with AI can do the work of entire departments, the fundamental premise of hierarchical organization collapses.
Sam Altman crystallized this shift in 2023: "In my little group chat with my tech CEO friends, there's this betting pool for the first year that there is a one-person billion-dollar company. Which would have been unimaginable without AI—and now [it] will happen."
This isn't an efficiency gain. It's a new species. Traditional structures assume human bandwidth constraints: managers exist because humans can only coordinate with 5-7 direct reports. Departments exist because specialization was mandatory. Approval chains exist because information couldn't flow freely.
AI eliminates these constraints. But most organizations are still structured for a world where they existed, like building highways after inventing teleportation.
The Velocity Arbitrage
Here's where the gravity well dynamic becomes decisive. Companies that achieve algorithmic efficiency with human teams don't just get first access to scarce chips and power—they can actually deploy them before competitors finish their planning cycles.
Consider the math:
Traditional enterprise: 18-month pilot → 12-month rollout → 6-month optimization = 36 months to value
Velocity-optimized org: 2-week prototype → 4-week deployment → continuous iteration = 6 weeks to value
That's a 24x advantage in learning cycles. In AI time, where models double in capability every six months, slow organizations are perpetually two generations behind.
The counterexamples prove what's possible:
Midjourney: $200M ARR with under 100 employees—no sales team, no marketing department, pure product velocity
Cursor: $100M ARR with 20 people, outmaneuvering Microsoft's 220,000
These aren't just lean startups. They're existence proofs that small teams with AI leverage can outperform giants with 1,000x more resources.
The Zero-Friction Organization
Traditional organizational structures are artifacts of pre-AI constraints. Why have three levels of management when AI can coordinate directly? Why maintain rigid department boundaries when AI agents can fluidly collaborate across domains? Why preserve approval chains designed for human processing speeds?
AI acts as an organizational superconductor, eliminating resistance between human judgment and machine execution. It enables structures that were previously physically impossible: dynamic teams that form and dissolve per task, decision-making that scales horizontally instead of hierarchically, and coordination without communication overhead.
Traditional software demanded you conform to its structure. Traditional organizations demanded the same. AI enables structure to emerge from the work itself, reforming moment by moment based on what needs to be done, with 10 times or 100 times fewer people than before.
The implication is stark. When execution friction approaches zero, when AI handles coordination overhead, when decisions flow at the speed of thought, traditional organizational mass becomes pure liability.
The companies that win won't be those with the most engineers. They'll be those who achieve the highest velocity with the smallest surface area. In an AI-accelerated world, organizational friction doesn't just slow you down—it makes you obsolete. Every management layer, every approval process, every coordination meeting is a competitive disadvantage that compounds daily.
This creates a triple lock on AI's future. Scarce packaging capacity flows to whoever can pay. Scarce power flows to those locked in contracts years ago. However, both advantages are negated if you can't deploy quickly enough to capture value. The companies that win all three—compute, power, and velocity—don't just get resources. They get to define what resources are worth.
When TSMC adds packaging capacity, it doesn't get distributed fairly. Apple takes first dibs on M-series chips, Nvidia fights for what's left, and AMD scrambles for scraps.
When a nuclear plant comes online, it doesn't power the grid. Microsoft or Meta locks it up with a 20-year contract.
When top AI engineers leave Google, they don't scatter across startups. They concentrate at Anthropic, OpenAI, or start their own labs.
This is the dynamic of the gravity well: scarce resources flow to whoever can pay the most and deploy the fastest. Three types of companies have positioned themselves at these choke points, each exploiting scarcity in a distinct manner. They don't compete for resources—they control how resources get allocated.
Three Winners
Foundation models grab every GPU that comes online and turn it into capability gaps competitors can't close. Accretive software platforms absorb every model improvement as pure margin—no engineering required. Infrastructure gatekeepers sit at the physical choke points and set their own prices.
Each type compounds its advantage differently. Each becomes harder to displace over time. And that's precisely what makes them investable. While startups fight for scraps, these companies get first pick of every freed resource.
Foundation Models: The FLOP Black Holes
A handful of organizations dominate enterprise large language model (LLM) traffic. OpenAI, Anthropic, Google, Meta, and a handful of Chinese labs don't just build AI companies—they build compute black holes that grow stronger with every GPU they consume.
The logic echoes Rich Sutton's bitter lesson: "The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin." Every efficiency gain flows directly into training larger models, not improving margins. When Nvidia releases H200s with 141GB of HBM3e memory—nearly double the H100's capacity—OpenAI doesn't pocket the savings. They train a larger model. When inference costs drop 10x, they serve 10x more queries.
The network effects are brutal. Better models attract more users. More users generate more revenue. More revenue buys more compute. More computing trains better models. The cycle accelerates.
The scale of ambition reveals itself in unprecedented infrastructure commitments. In January 2025, OpenAI, Oracle, and SoftBank announced Stargate—a $500 billion AI infrastructure project that dwarfs the GDP of entire nations. They're already pouring concrete in Texas, with 10 data centers under construction, each spanning 500,000 square feet. The initial $100 billion deployment alone exceeds what most countries spend on their entire infrastructure in a decade. This isn't a plan or a proposal—it's capital allocation at a scale that redefines what "compute investment" means.
Most AI software competes with advances in AI. Smart platforms surf them.
The distinction is crucial. Competitive software fights each model improvement—their moats erode with every API update. Accretive software absorbs improvements automatically. Model advances become margin expansion—no product changes required.
The Zero-Code Margin Machine
Tesla replaced 300,000 lines of C++ code with 3,000 lines that activate neural networks. That's the future of software: massive capability gains with radical simplification. Now, imagine applying that principle to business models.
When Mistral released its sparse mixture-of-experts architecture, activating only 13 billion parameters despite having 47 billion total, platforms didn't need to rewrite anything. They swapped models through existing APIs. Customers got 47 B-parameter quality, while platforms incurred 13 B-parameter compute costs. Whether platforms lower prices, expand usage, or capture margin, every efficiency gain strengthens their position.
This pattern repeats everywhere:
Tesla FSD collapsed 300,000 lines of driving logic into neural networks. Each model improvement now deploys instantly—no code changes required.
Palantir AIP supports OpenAI, Anthropic, Meta, and xAI models interchangeably. Users switch models in Pipeline Builder based on specific use cases, eliminating the need for re-engineering.
Vercel v0 upgraded from Claude Sonnet 3.5 to Sonnet 4.0. Error-free generation jumped from 64.71% to 93.87%. Their pricing stayed identical—pure margin expansion.
The evolution is inevitable: from swapping models to routing queries in real-time. Vercel already routes simple edits to models 40x faster than GPT-4o-mini, while complex tasks hit frontier systems. Glean's platform auto-selects from 15 LLMs based on each task's requirements.
The endgame? A compute exchange where every query finds optimal price-performance routing. Where model providers compete on microsecond latency and fractional cent pricing. Where enterprises never directly access model APIs.
The business model is antifragile. Every breakthrough in model efficiency, every new open-source release, and every API price war make these platforms stronger. They're selling picks and shovels, but the picks sharpen themselves.
That's not software. That's infrastructure for the AI age.
Infrastructure: The Physics Toll Collectors
You can't download a fab. You can't fork a power plant. You can't digitize an electron.
While software scales infinitely, the physical layer scales linearly—or not at all. This creates natural monopolies at every choke point in the AI stack. The companies sitting at these gates don't compete on code velocity. They compete on mastering the physical world—atoms per wafer, electrons per datacenter, years to build.
Advanced Packaging
One company controls 90% of the technology that makes AI chips work. They raised prices by 20% last year. No customer defected—there's nowhere else to go.
These aren't technology companies. They're toll collectors on the only roads to the future. Their moats are measured in construction years and billions of capital. Their pricing power comes from physics, not features.
History whispers its lessons: every generation's immutable constraint becomes the next generation's solved problem. Aluminum commanded gold's price until the advent of electrolysis made it commonplace. Bandwidth choked innovation until fiber made it infinite. Computing power itself was precious until transistors made it ubiquitous.
Today's physics bottlenecks—the packaging limits, the power constraints, the human friction—feel permanent because they are physical. But physics has always been negotiable, given enough intelligence applied to the problem.
The next decade will witness history's greatest resource arbitrage. Those who control today's scarce atoms—the wafers, electrons, and decision-makers—will shape how intelligence itself evolves. They'll determine which ideas get computed, which companies get power, and which innovations see the light.
But this isn't a story about eternal monopolies. It's about transition states. The most fascinating moment won't be when these constraints bind tightest, but when they begin to crack—when someone figures out optical computing, when room-temperature superconductors arrive, when organizations achieve zero coordination overhead, when AI systems learn to design their own infrastructure.
The companies positioning themselves at these choke points aren't just collecting tolls—they're funding the research that will eventually render them obsolete. TSMC's packaging monopoly funds the photonics research that could eliminate the need for packaging. Nuclear moonshots teach us about distributed energy. Today's organizational friction accelerates tomorrow's autonomous systems.
We stand at a unique moment: bright enough to see the constraints, not yet clever enough to route around them all. The gap between what intelligence wants to do and what physics allows creates the defining economic dynamic of our time.
Physics always wins—until it doesn't. And then everything changes.